Our game was hosted at http://ehzhang.me/snap-sim. Game testers were given a random family size and weekly food budget, and were told to select food items within their budget that would allow them to eat healthy.

After playing, they were directed to a google form that recorded their food budget, family size, resulting score, and the amount of money they had leftover. They were also asked to answer the following questions:
- Did your score surprise you? If so, why?
- Did you have to make any sacrifices (ex. not getting a food you wanted) because of your budget?
- How much money do you think a person needs per week in order to eat healthy?
Feedback
Average given family size: 3.5
Average given food budget: $185
Average final score: 48.98
Average money leftover: $59.97
Many people found that our game was fairly easy, though people who ended up with bigger families and smaller budgets tended to find the game more difficult. There were many testers who were surprised at their final score at the end, since they purchased food they would normally eat.
Responses to how much money a person needs per week were across the board, though more people tended to think that less was best.
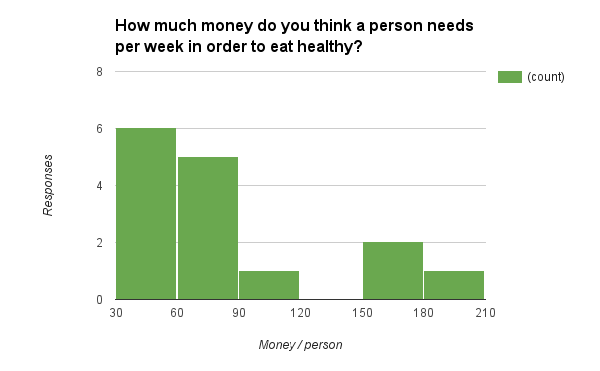
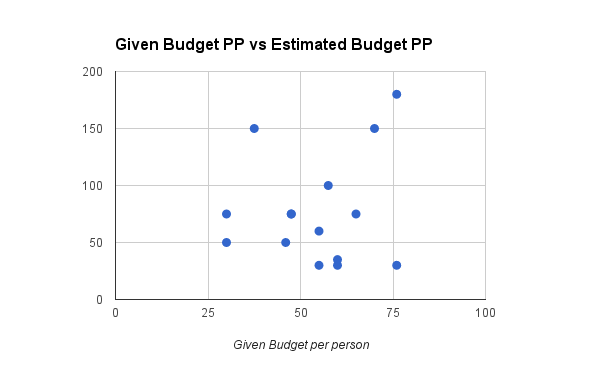
The estimates didn’t seem particularly correlated with their given family sizes. So we decided to look if there was any correlation between the tester’s given budget per person in the family, vs their final response:
Some responses to sacrifices focused on food items that were not a part of the game, such as rice, wheats, condiments, and beverages like coffee or tea. Other testers mentioned that they had to cut out fast food or junk food and snacks for the sake of their budget. One tester mentioned that while they would have loved to buy more fruits and vegetables, because they don’t provide a lot of calories, they would be a bad choice with a very limited budget.
For the testers that received a lot of money, they felt that the game was so easy that they didn’t have to make any sacrifices.
Changes
If we had more time to work on this, we would play around with different ways of displaying the game to make it more engaging, as well as adding more food items that people have mentioned that weren’t there. We would also make the game more difficult, since the goal is to start a conversation with how hard it is for some SNAP users to eat healthy. Other changes include not allowing people to enter negative amounts to gain money, and adding discussion about how the score is calculated. Something else to include is more familial context — grocery shopping is very different with children or expectant mothers in the midst, and these situations can make the experience more realistic and thought-provoking.