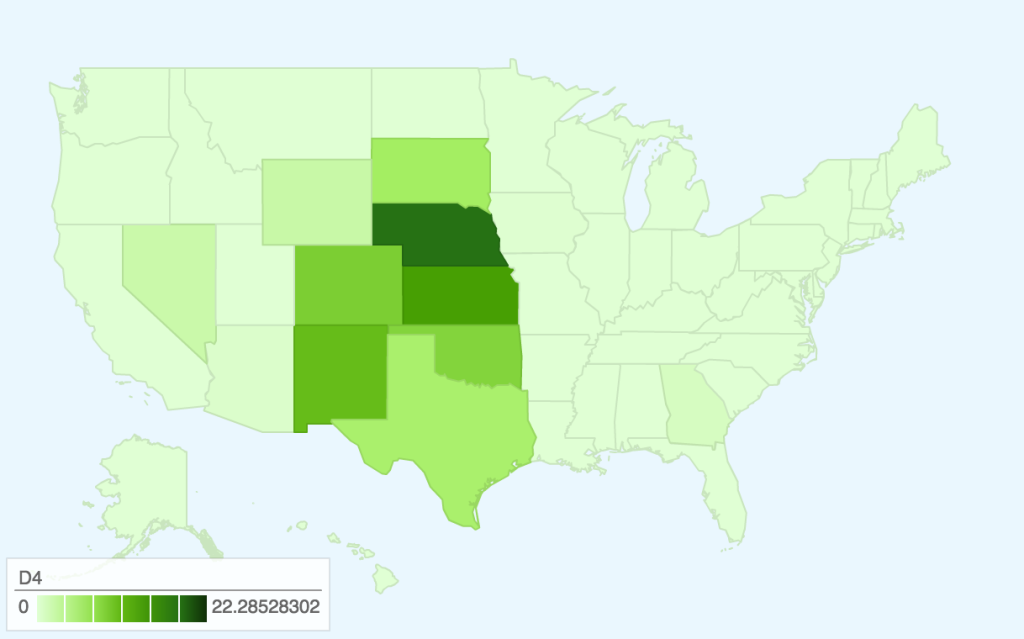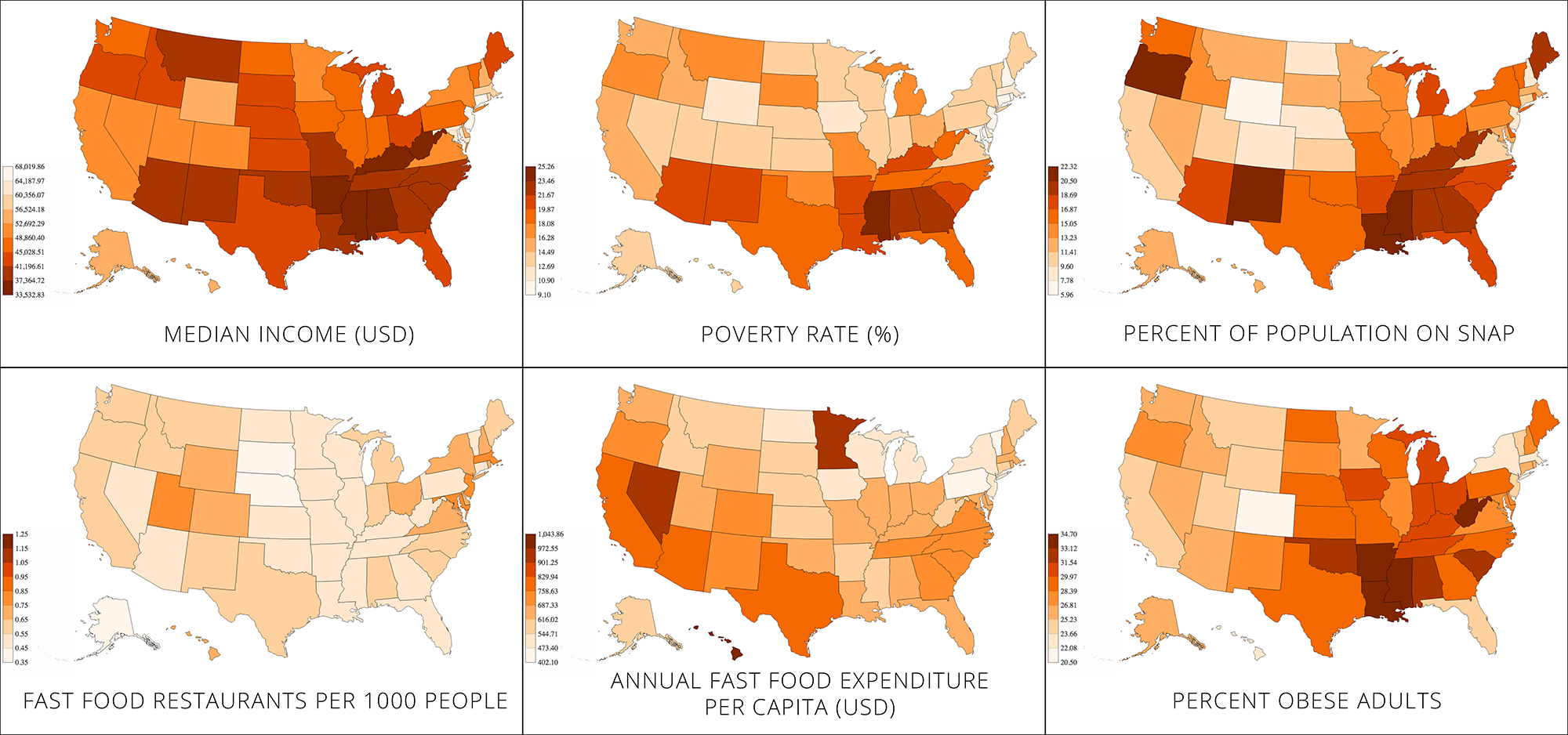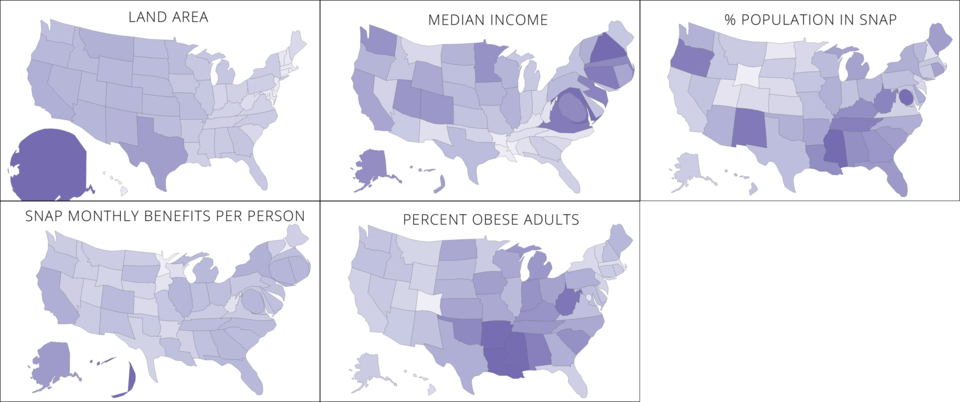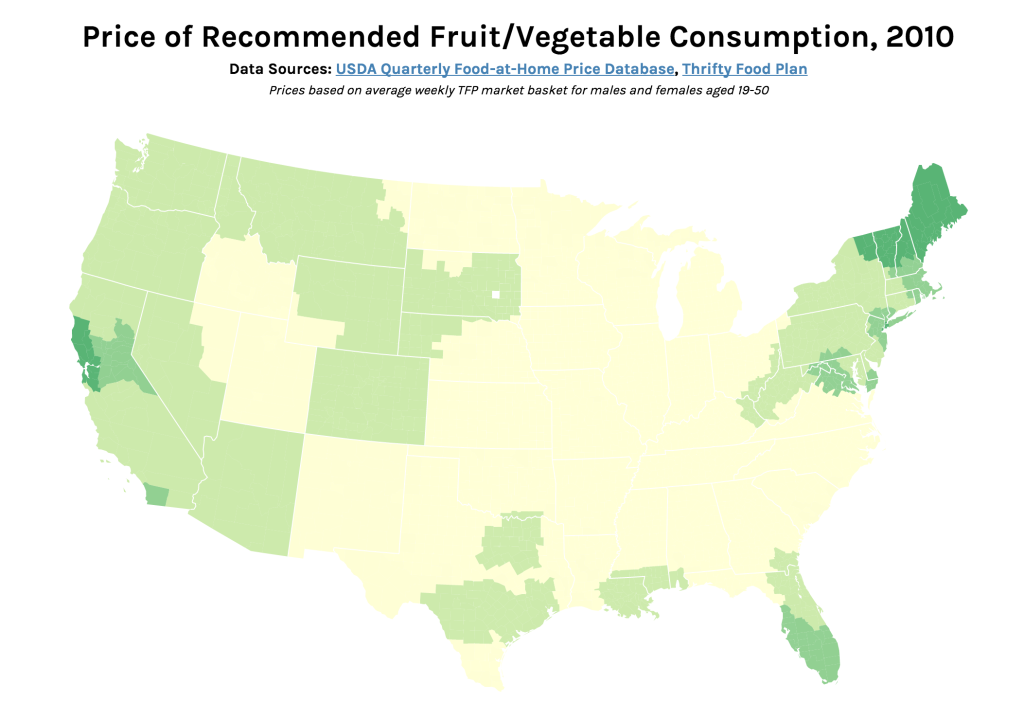
Interactive version: http://s2tephen.github.io/qfahpd/map/
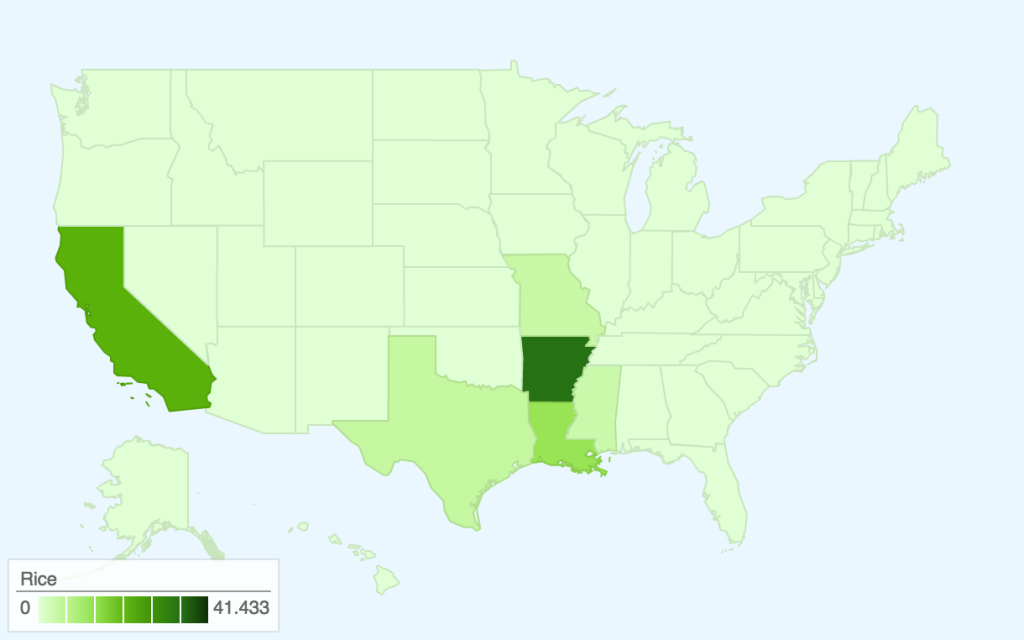
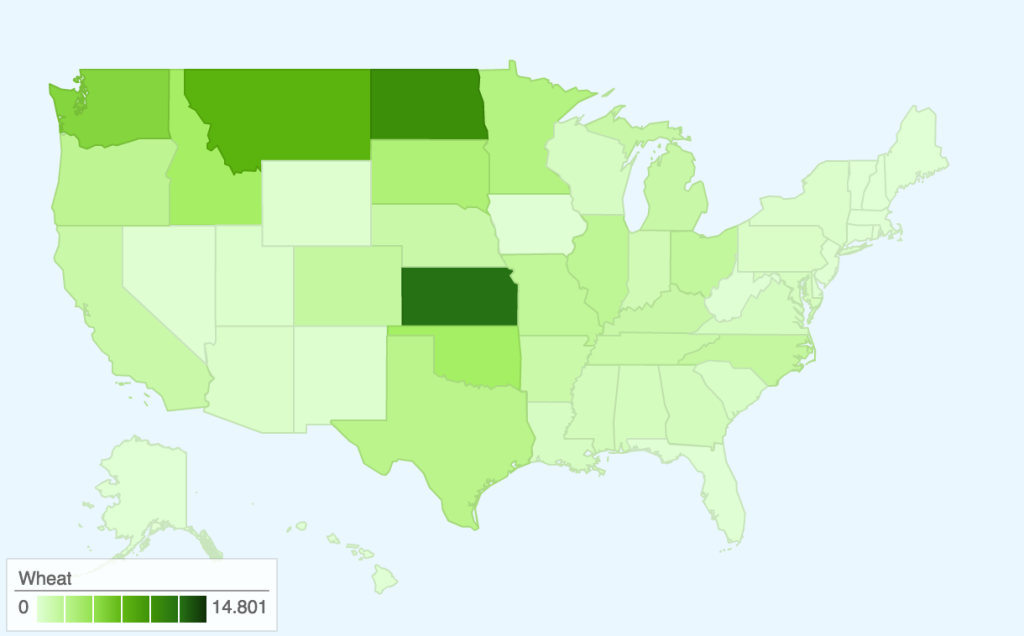
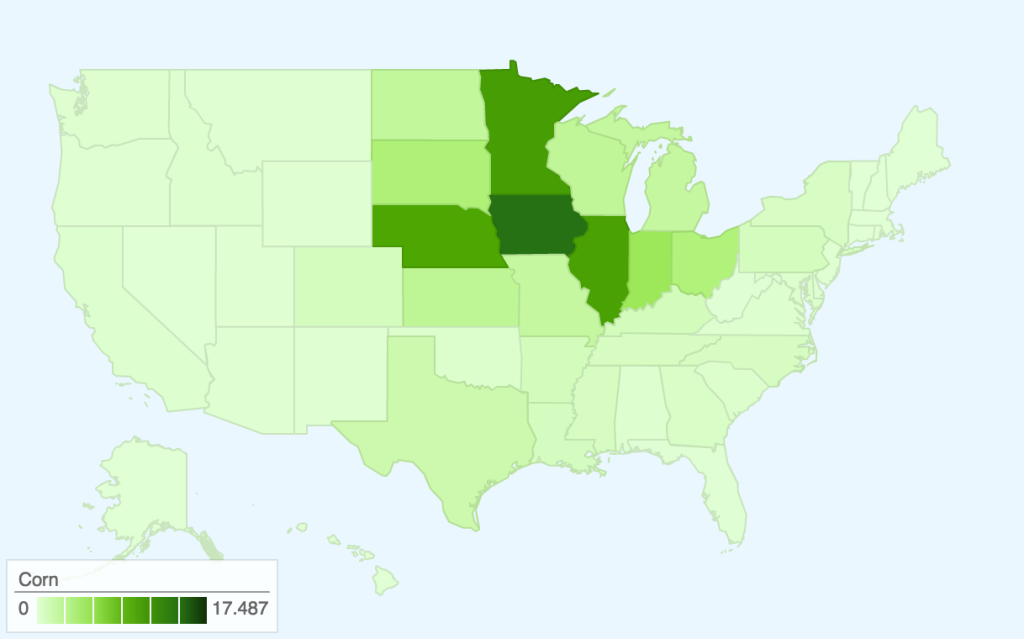
This map takes the two data sets we worked with previously — the Quarterly Food-at-Home Price Database (for the small multiples of fruit/vegetable prices) and the Thrifty Food Plan (for the SNAPables data sculpture) — and attempts to synthesize them to tell a single data story. In our presentation of the food price data, one of the criticisms we received was that price per 100g of food was not an intuitive way to think about food consumption. The Thrifty Food Plan, the bare minimum of an adequate diet (and the basis for calculating SNAP benefits), actually includes the breakdowns of its market baskets by weight (pounds). This meant that we could actually calculate the real price of the Thrifty Food Plan around the United States, factoring in regional price differences.
Most of our time was spent cleaning and synthesizing multiple data sets, so once again we only had time to focus on the fruit/vegetable food group. However, the next step for this map would be to calculate the combined price of all food groups (i.e. the entire Thrifty Food Plan market basket) and compare this to the SNAP amount. This is because the cost of the Thrifty Food Plan is based on the assumption of uniform food prices across the nation — however, as the Quarterly Food-at-Home Price Database shows, this is simply not the case. We could then identify which regions’ SNAP benefits may be over- and underestimated.
As such, the audience for this graphic would be the researchers and policymakers responsible for creating the Thrifty Food Plan and setting the SNAP benefits. The goal of the combined map would be to advocate for a new SNAP benefit methodology, based on actual local food prices. For this iteration, we only included data for those from age 19-50, but one could imagine an even more interactive version of this graphic, where someone might specify their age/sex and weekly spending on food — the map could show them the weekly required spending for an adequate healthy diet, allowing them to compare those numbers.
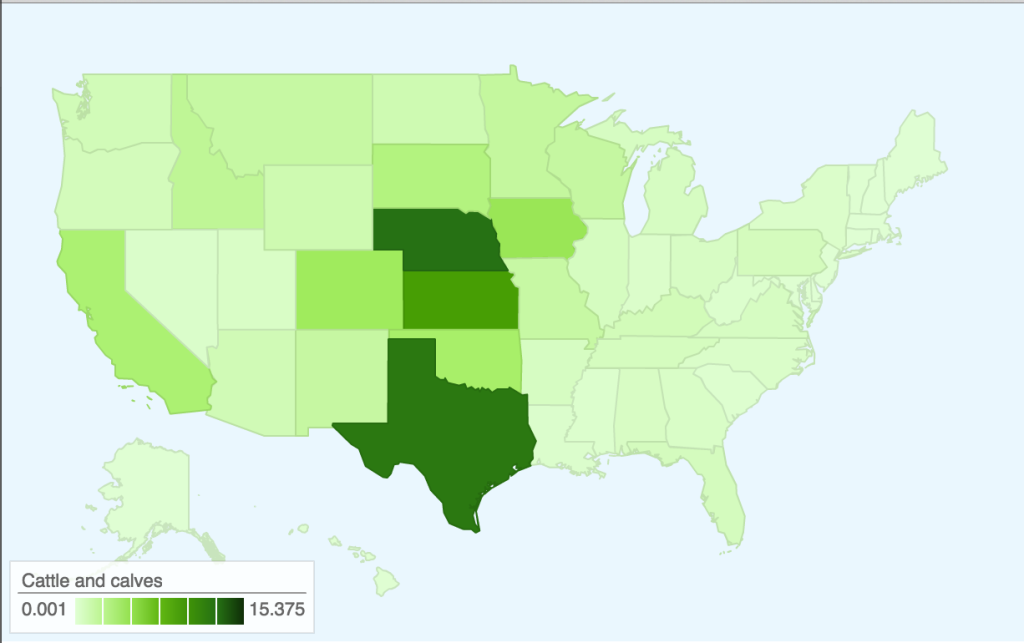
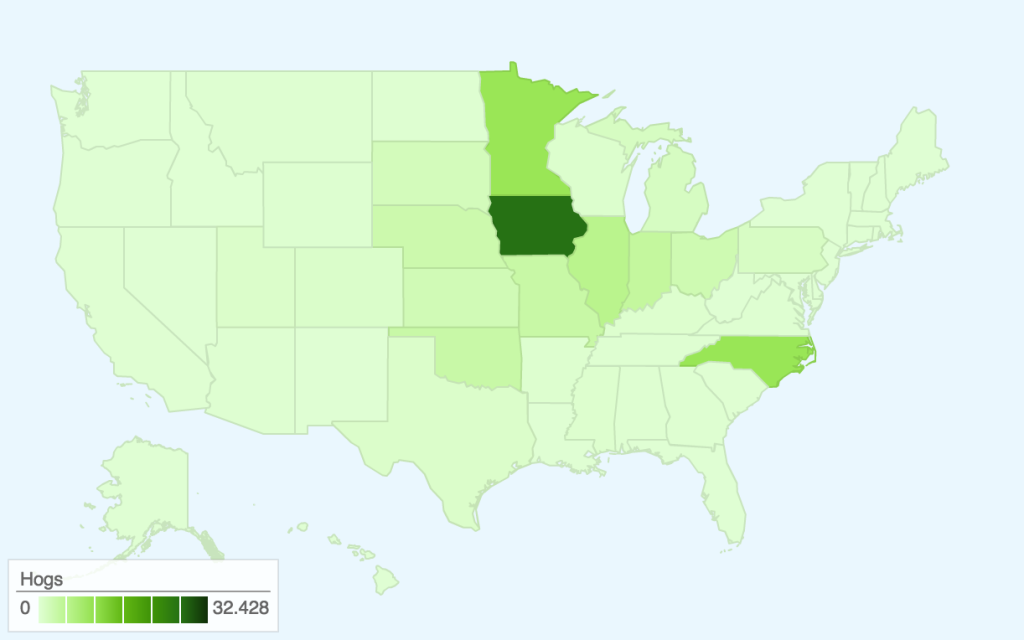
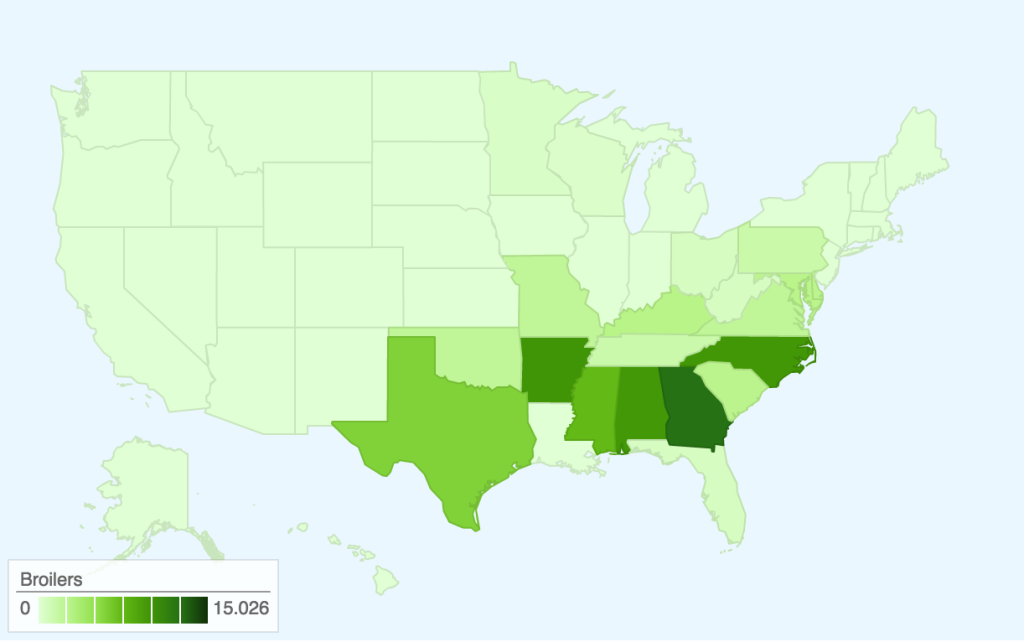
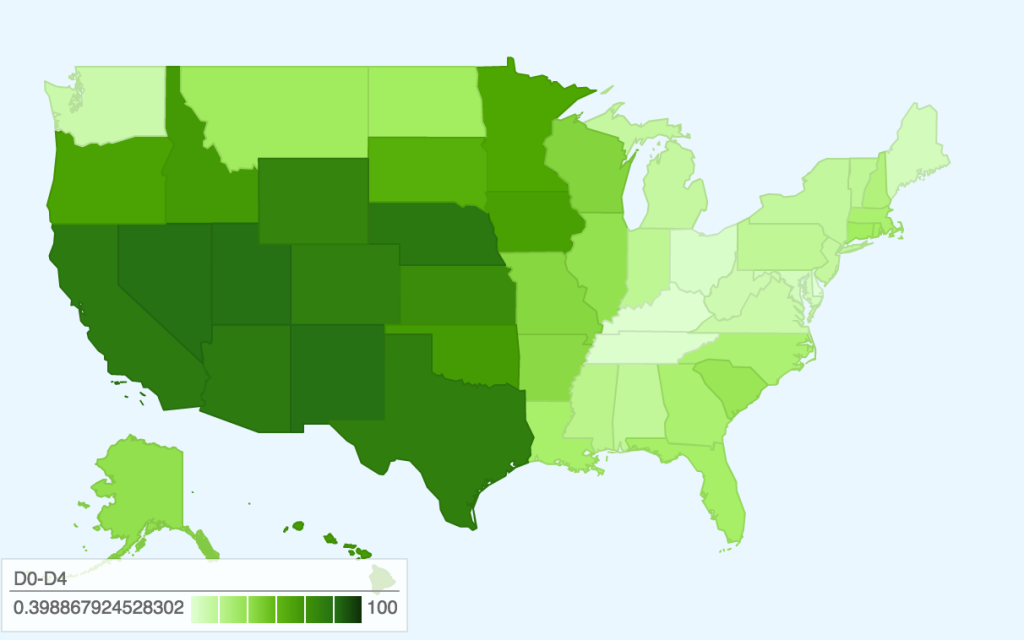
In terms of data visualization, this choropleth was created in D3.js/TopoJSON and uses quantile classification to subdivide the different weekly spending amounts on fruit and vegetables. ColorBrewer was used to generate the colors, but the large area of yellow is kind of hard to see (perhaps we could have used a different color ramp or adjusted the classification buckets to improve this). Furthermore, the map would be a lot more readable (i.e. as a static graphic) with a legend — as it is currently, you only get a broad comparative view of the country and can only really zoom in on actual prices if you use the interactive version. Another minor thing is, because the data is regional and not at the county-level, having each county as an individual entity is kind of useless (the counties don’t conform to traditional political boundaries, so this was the best we could do). The other question is whether a map is actually the most appropriate visualization method — even if there are significant differences in food prices based on geography, we might need to make some hypotheses or incorporate additional data sets to explain how geography might be affecting variation in prices.