Danielle, Edwin, Harihar, Tami
SnapSim is an interactive text-based narrative in which a player takes on the role of a single parent on SNAP shopping for food for themself and their two children. Each food item has a story indicating its importance to the family, and the narrative forces the player to forgo some foods in order to stay within budget.
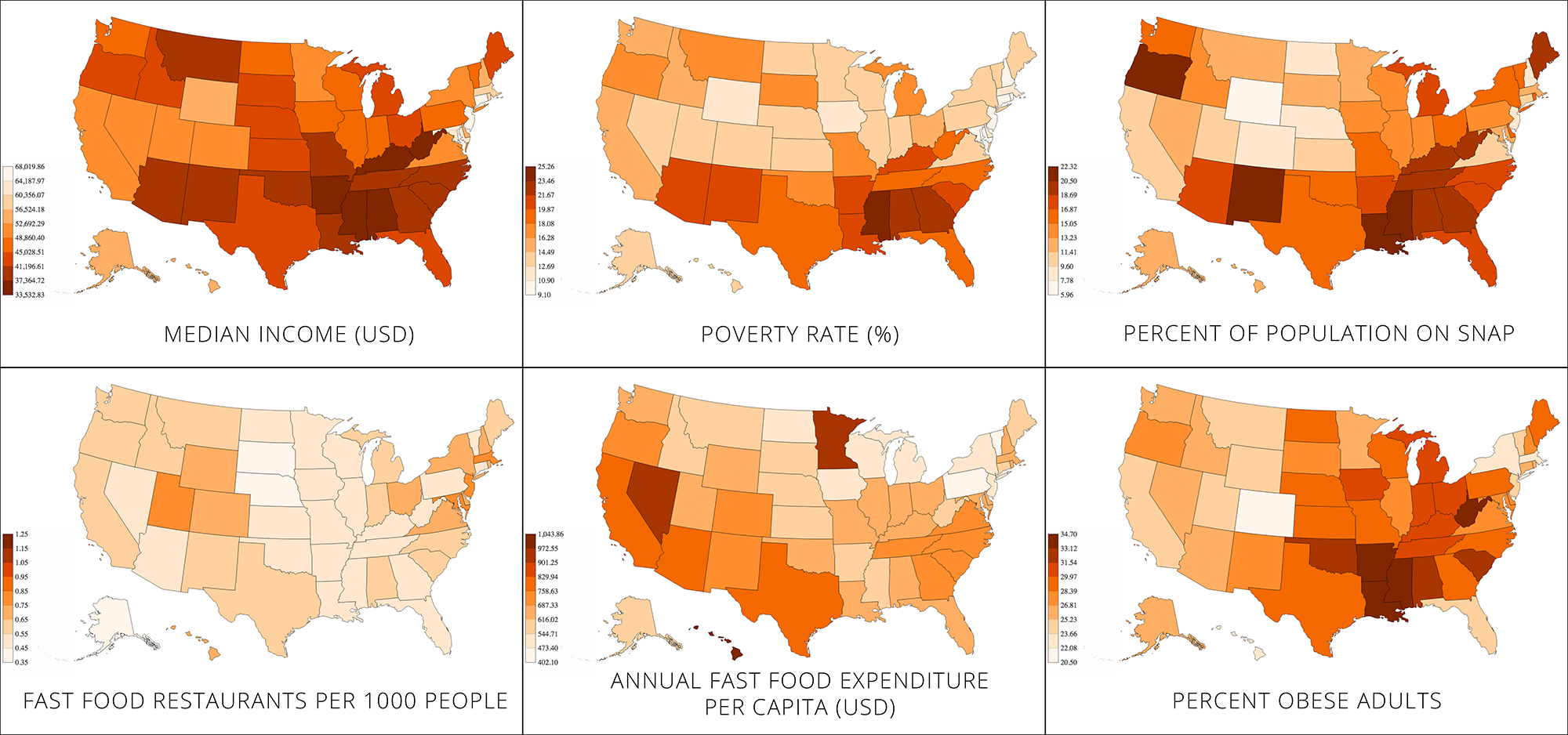
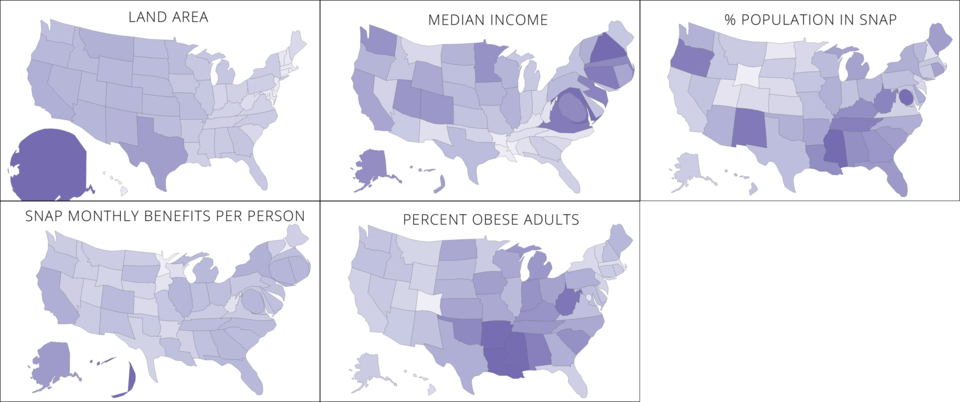
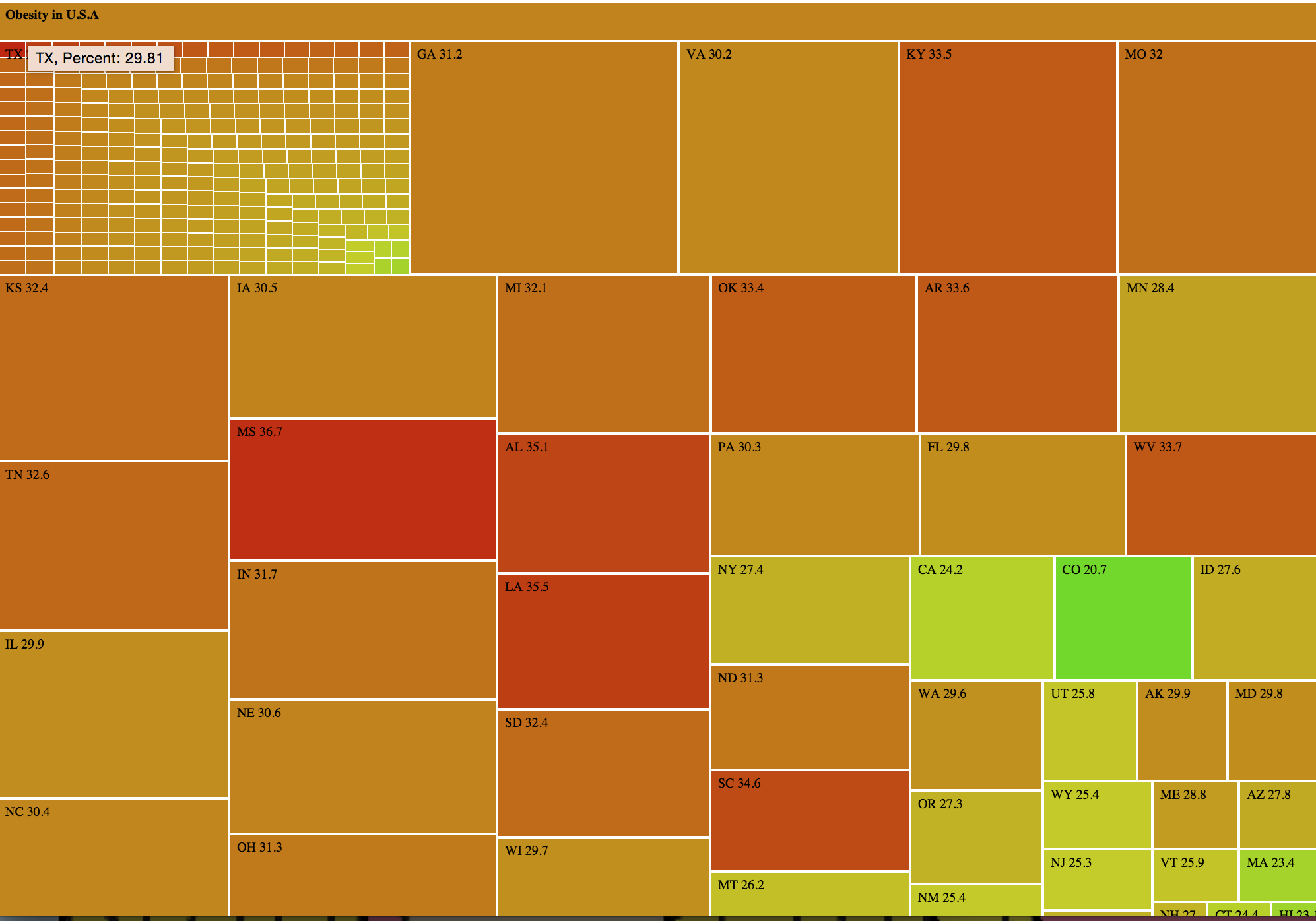
The goal of the project is to evoke empathy in our audience by simulating some of the challenges faced by a family shopping on SNAP. We chose this goal because, as we did our weekly mini-assignments, we found that publicly available datasets and visualizations failed to capture the challenges faced by the individual family on SNAP, but instead focused on aggregates (ex. obesity percentages by state). Therefore, we aimed to make a data story which would humanize the data and effectively illustrate the sacrifices that families on SNAP make in a way that numbers could not. We hoped that such a data story would cause the player to feel empathy for such families.
Our target audience was people who were not SNAP participants and who were from middle-class or rich households because they were least likely to be experiencing the same challenges as those faced by families on SNAP. Because MIT students were readily accessible participants, our study focused on them.
We created two variants of our interactive narrative. We tested each variant with four different players. We each sat with the players and guided the experience. At the end of the narrative, we tied it back to reality by showing the player a map indicating SNAP participation around the country. Then, each player completed a survey giving feedback on the experience.
Based on interaction with players and the feedback in the surveys, we made a number of observations. First, all of the players remarked that SNAP does not give enough money to families (see quotes below). However, some of the player responses may have been due to prior belief rather than SnapSim.
“I have always been pretty skeptical of SNAP as giving people enough money to eat “
“Just learned about SNAP. its a good idea but [it] doesn’t seem like a lot of money to buy groceries”
“86 dollars is really low for three people”
Six of the players indicated that $100-$150 (rather than the allotted $86) would be more reasonable to buy groceries.
In addition, all but one player indicated that SNAP requires sacrifices.
“Yes. I felt bad buying things that were unhealthy because I knew that I wouldn’t have enough money to buy both. At the same time, I didn’t want to buy food that would go bad because the kids won’t eat it.”
“Well I had to get rid of half of my groceries soooo. I didn’t like having to get rid of all the things my kids like. I also didn’t like that I had to choose all or nothing on each item – I couldn’t alter the amounts or exchange chicken breast for thighs, etc.”
“When I started I added lots of stuff to cart because I thought I needed them. I spent over 100 dollars and had to give up a lot of stuff”
Finally, after showing the map of SNAP participation rates and food banks, every player said that they would be interested in volunteering or donating to a local food bank some time in the future. While showing players how they can help is valuable, we can’t know whether they actually will volunteer.
It is difficult to measure empathy, but the results of our testing seem promising. The players were able to recognize that shopping on SNAP requires some difficult sacrifices,, and that they would be interested in helping out a food bank.