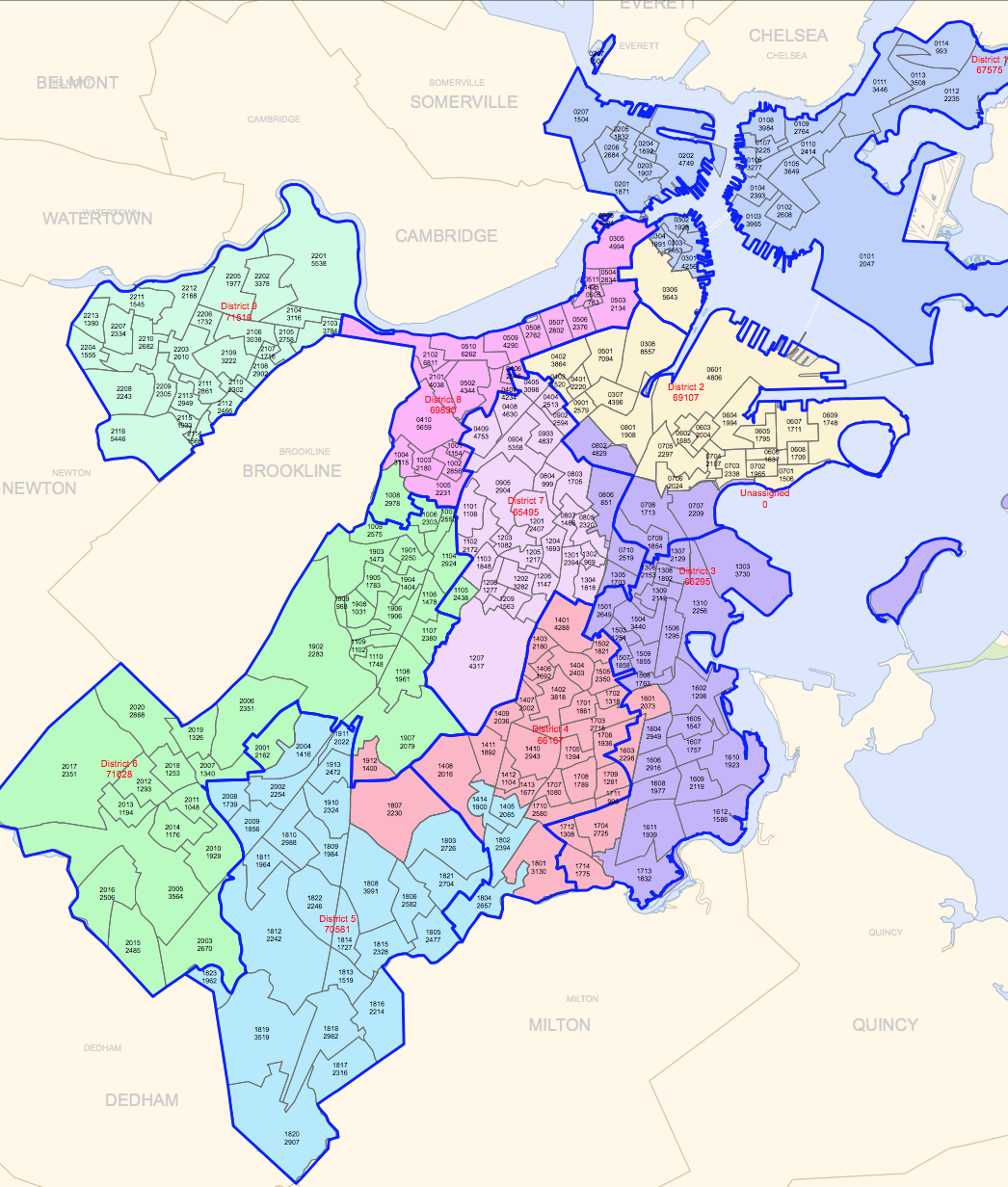
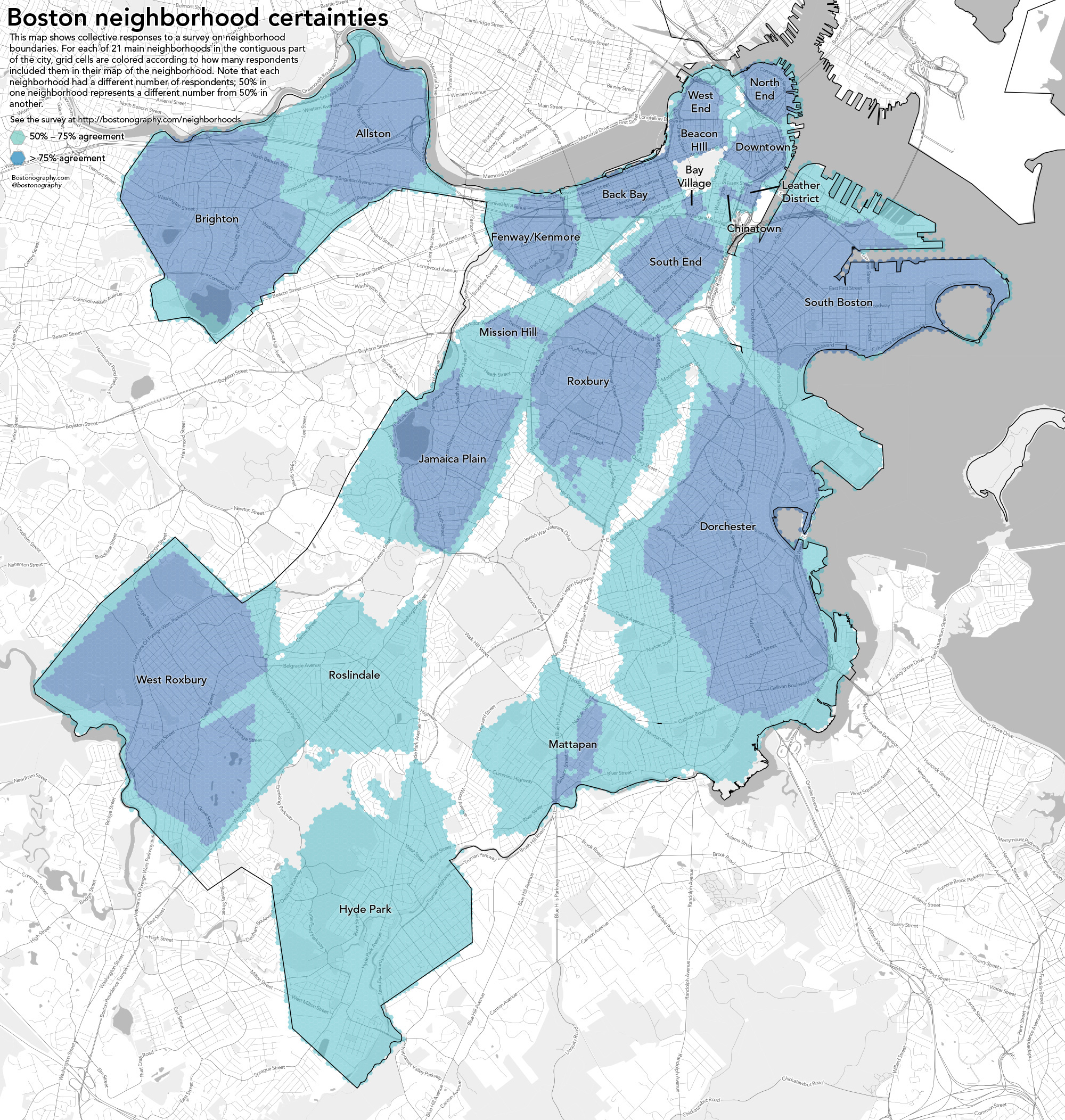
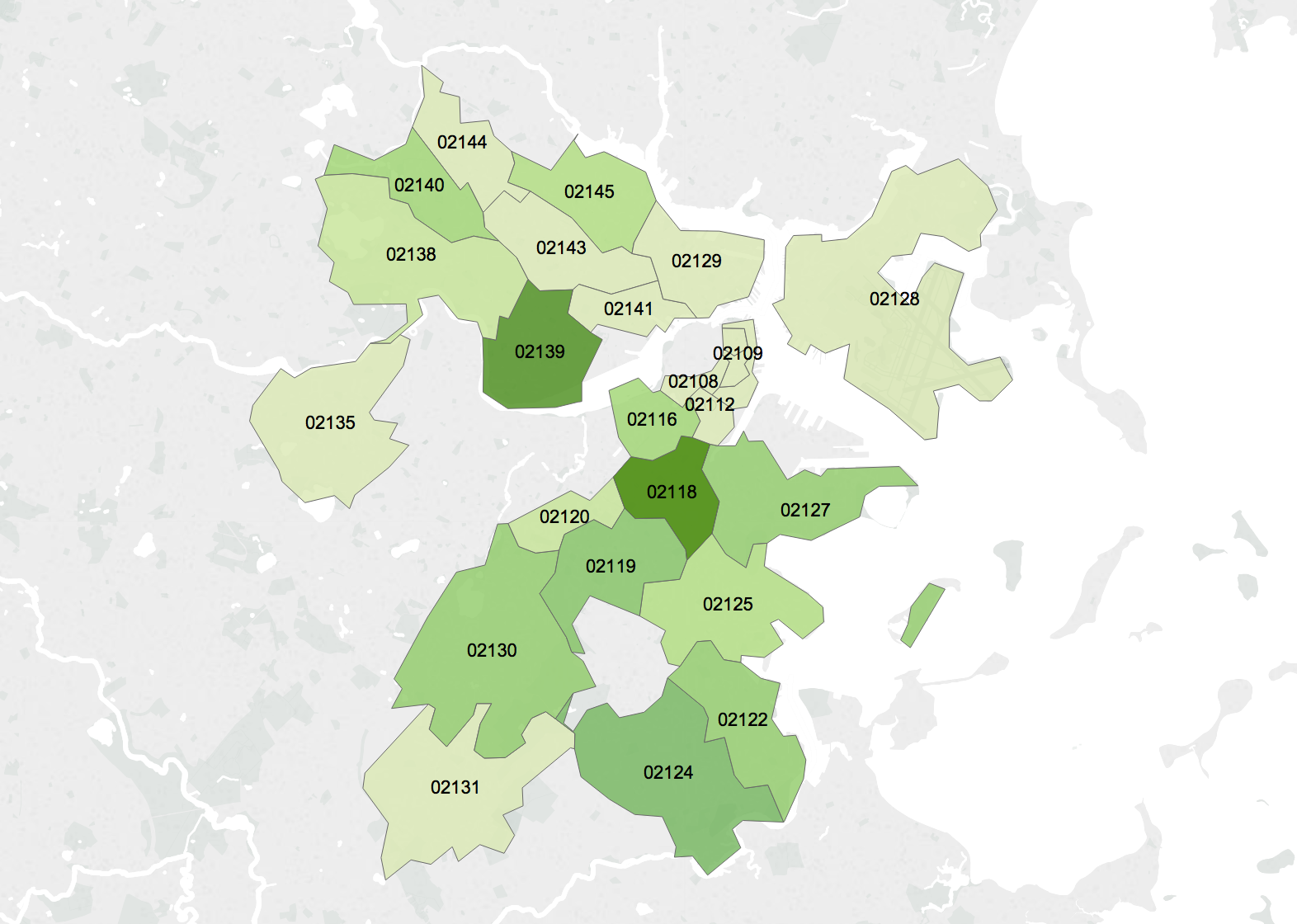
R is a free open-source statistical programming software descendant from S that came out of Bell Labs. Rstudio is a commonly used user interface for R. Both can be downloaded for Mac, Windows, or Linux. R is widely used and established–it is highly unlikely that it will disappear anytime soon.
R is great for custom data visualizations and advanced statistical analysis. It also forces you to be structured and repeatable in your data analysis–the process of interacting with your data requires explicitly writing out the steps of interaction, unlike Excel or similar approaches. Once you have powered through the learning curve you can quickly summarize and visualize your data.
Lots (a majority?) of statisticians use R and share their most recent work through R packages that extend the functionality of “base R” (the initial installation). Packages that I commonly use include: RColorBrewer, plyr, ggplot2, lattice, stringr, reshape2, and there are many other useful packages out there. Some additional suggestions can be found here and googling will lead to many more results. R also offers a variety of open source datasets both as a part of a package or the purpose of the package, such as the census data. R also includes communities supporting particular aims, such as the rOpenGov project.
R does a good job of handling situations common to real data analysis such as missing values or cleaning strings. It can handle large data (and even Big Data) through a variety of packages such as pbdr. It can also be used with qualitative or social science data. It can be used to create maps. It can be used with LaTex (via, for example, Sweave) and websites (via, for example, shiny) so your analysis can be directly embedded in your output files. This can be very convenient and reduce errors as your data processes update or your datasets change based on new information.
R is somewhat difficult to learn, though there are extensive online resources the helps the process. Resources include:
- The R-help mailing list. A great resource, but use with caution–google first! Someone has probably asked your question already (especially in the beginning).
- A collection of R blogs. Great for keeping up with new work in the area and getting a scan of what’s out there.
- Blogs for starting off with R, for example or resource lists.
- Blogs for newer R users, for example, or this, or many others.
- R FAQ. Useful, but not the most easily accessible document when you’re first starting.
- The R Conference. An intense group, but a lot of fun and very informative.
R does some fun things too, like:
- displaying your favorite xkcd cartoon
- creating animations
- telling your fortune
- playing games (minesweeper, sliding puzzles…) with the fun package
- talking to twitter
I would (and have!) definitely recommend R to a friend. I’d like to do something more physical than visual for my final data story, but I plan to use R for the initial data exploration and cleaning…and it’s possible I’ll get so sucked in to that work that I’ll end up staying the visualization space.