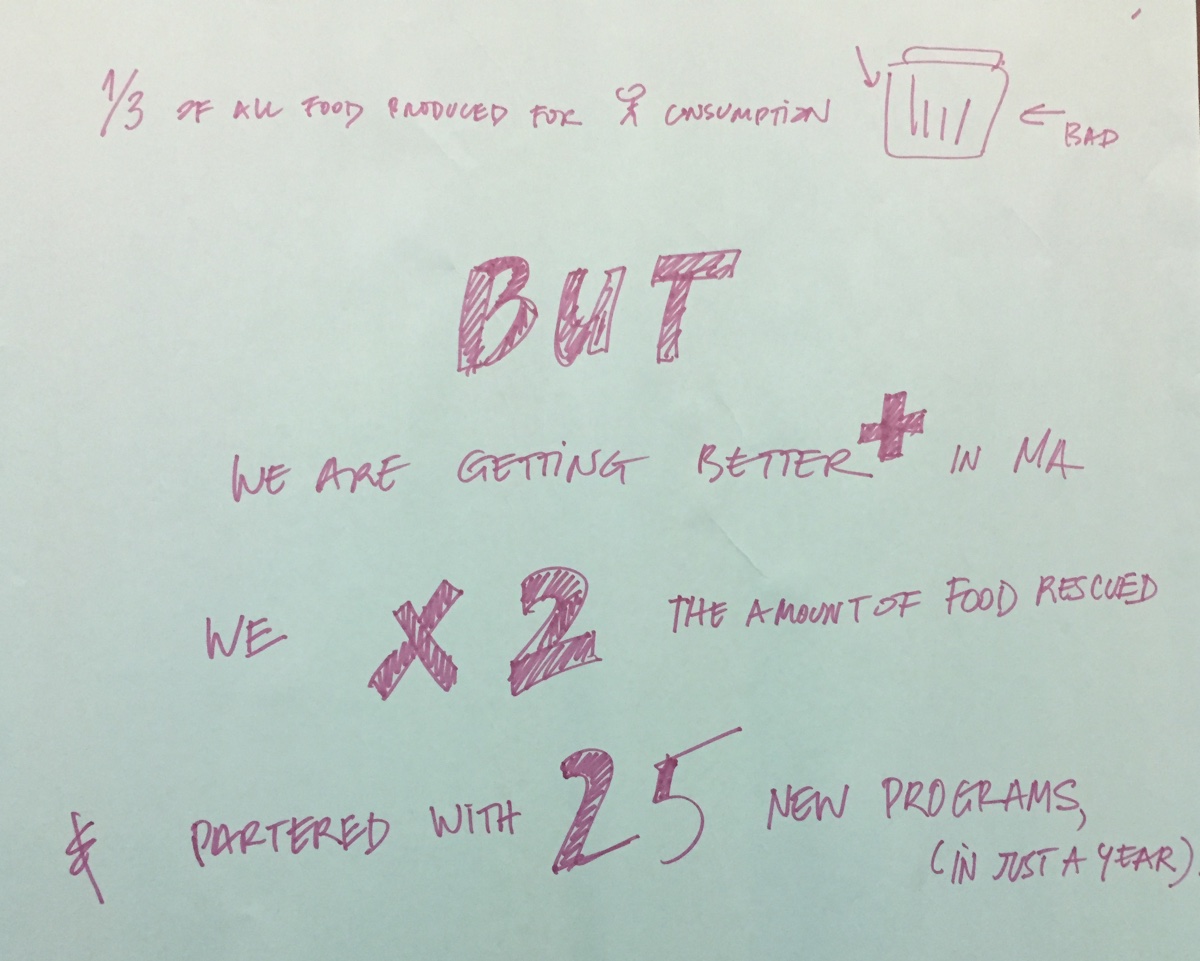Interestingly, our story-finding began with Sasha Purpura telling us the mission of Food For Free. The goal here was not to have a story given to us, but to help us find a story in the data. “Start With the Data, Finish With a Story” mentions the importance of of having a “clearly defined objective in querying the data”. After understanding the context from Sasha’s story, we could pose questions and see if they were supported by the data. In this way, the data guided the mural’s story.
By going through Rahul’s taxonomy for data stories, our approach was similar to that laid out in “Data Stories”. Specifically, we looked at changes over time, associations, and comparisons. While it was not as common, we also used the “blacklist” approach described in “Start With the Data, Finish With a Story”. For example, my group looked at the quotes, which were quite positive, trying to identify something that recipients still needed. Our examination indicated that there isn’t much dairy rescued, which could be an interesting story to pursue.
At the end of story-finding, we wrote the story in a couple short sentences. “Start With the Data, Finish With a Story” says that a data story should “hit [readers] with a headline figure that makes them sit up and take notice”. By writing the story so concisely, we were able to make our mural communicate the “headline” of the story.
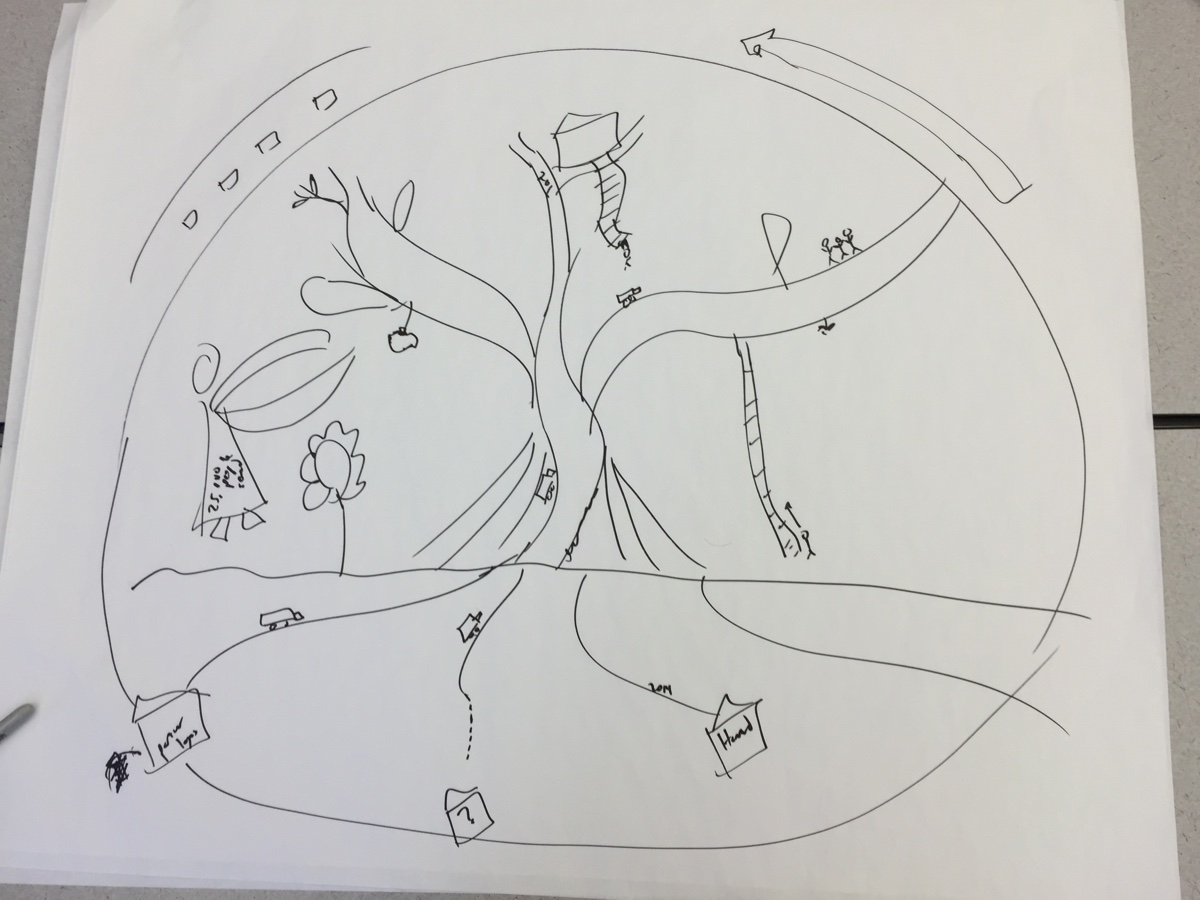
Since it is not interactive, our data mural is primarily author-driven. However, as ceriley mentioned in the post below, it is partly reader-driven because the reader may choose what to focus on. The mural design contains a number of small components (ex. trucks coming up roots, donor names on the buildings on bottom, actions of individual people) that are not as immediately noticeable as the tree itself. Unlike other visual narrative styles, such as infographics, the mural does not prescribe an order for the reader to follow. Instead, the reader is free to examine each component in any order. In this way, we can argue that it is partially reader-driven.
Although it is not a video, since our design contains several components, we need a way to preserve continuity as the user looks at different parts of the mural. Continuity is maintained through the tree – all the components (ex. trucks, donors, people) are interacting with the tree in some way.